Context
Last week, I explored how changing the decision threshold affects model behaviour.
This week, I removed the threshold entirely — and something clicked.
The Shift
The model never actually made decisions.
It only produced scores.
Each prediction is a probability — a measure of how likely something is to be positive.
The “decision” only appears when we impose a threshold on top of those scores.
Why This Matters
That reframe changes how models should be evaluated.
The important question is not:
“Is the prediction correct?”
It is:
“How well does the model rank what matters?”
What I Explored
Instead of focusing on a fixed decision threshold, I looked at the model’s raw outputs.
- Generated predicted probabilities using
predict_proba - Compared binary predictions vs probability scores
- Plotted ROC curves
- Plotted Precision–Recall curves
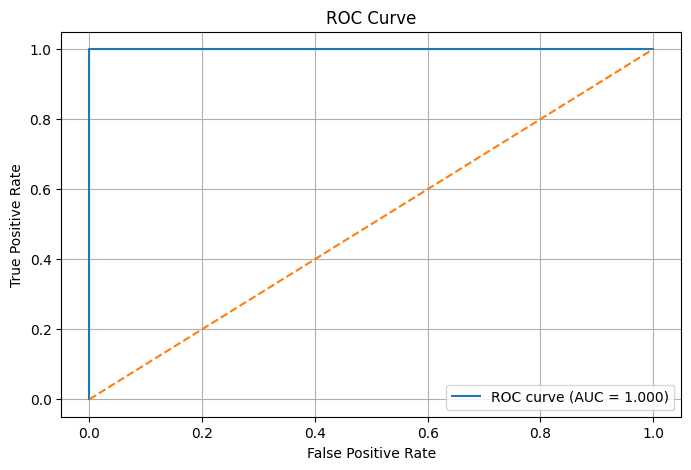
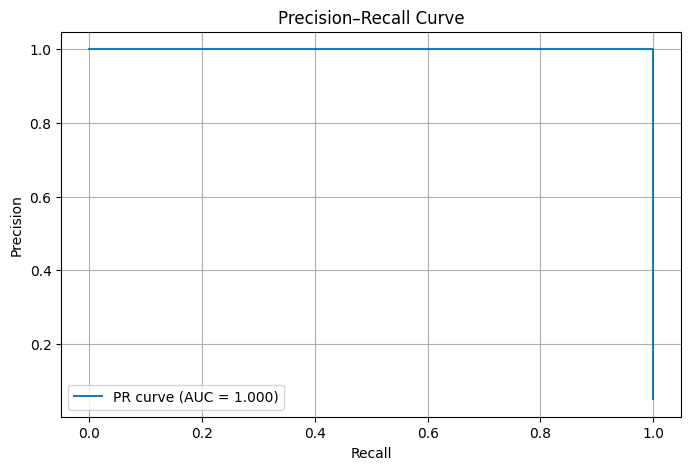
These curves evaluate model behaviour across many possible thresholds, rather than locking evaluation to a single decision point.
Real-World Framing
In systems like fraud detection, credit risk, and affordability:
- We prioritise the highest-risk cases first
- We treat different score bands differently
- We apply actions based on levels of risk
A fraud system, for example, doesn’t decide “fraud or not.”
It ranks transactions by risk — and different actions are applied at different levels.
What Became Clear
A model can look accurate, behave differently across thresholds, and still be poor at ranking.
Accuracy alone does not capture that.
What’s Next
Next, I’ll explore ROC-AUC and Precision–Recall AUC more explicitly — and how they help compare models beyond a single decision point.