In my first classification experiment, the main goal was simple: get a basic model running and understand the flow from input data to prediction.
That was a useful starting point, but it immediately raised a more important question:
How do I know whether the model is actually doing a good job?
At first glance, accuracy seems like the obvious answer. If a model is correct most of the time, that sounds reassuring.
But the more I look at classification, the more I’m learning that accuracy can be a very incomplete story.
The problem with accuracy
Accuracy tells us how often a model is correct overall.
That sounds reasonable, but it can become misleading when the classes are not evenly balanced.
Imagine a dataset where 95 out of 100 examples belong to one class, and only 5 belong to the other.
A model could predict the majority class every single time and still achieve 95% accuracy.
On paper, that looks excellent.
In practice, it may be missing every single minority case.
That is the part that matters.
Why imbalance changes the picture
This is the basic challenge of imbalanced classification.
Not all classes appear with the same frequency. In many real systems, the most important outcomes are rare:
- fraud is rarer than normal behaviour
- failure is rarer than success
- exceptions are rarer than routine cases
- risky events are rarer than harmless ones
That means a model can perform well on the common cases while failing exactly where attention is most needed.
So the question is no longer just:
“How often is the model correct?”
It becomes:
“What kinds of mistakes is the model making?”
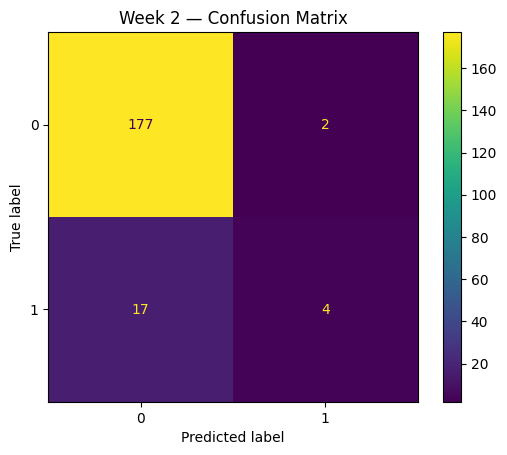
A better lens: the confusion matrix
This is where the confusion matrix becomes useful.
A confusion matrix breaks predictions into four buckets:
- true positives
- true negatives
- false positives
- false negatives
That structure forces a more honest view of model behaviour.
Instead of hiding mistakes inside one summary number, it shows the shape of the errors.
And that matters, because not all mistakes have the same cost.
A false positive may create noise.
A false negative may miss the very case you cared about finding.
That is not just a statistical detail. It is a system design problem.
Precision and recall
This is also where precision and recall start becoming more meaningful than accuracy alone.
Precision
Precision asks:
When the model predicts a positive case, how often is it right?
This matters when false alarms are expensive or disruptive.
Recall
Recall asks:
Of all the real positive cases, how many did the model actually find?
This matters when missing an important case is costly.
That trade-off is one of the first things that makes model evaluation feel real to me.
It is not just about getting a higher score.
It is about deciding which type of error is more acceptable in a given context.
Why this matters beyond toy examples
One of the reasons I want to understand this properly is that real-world systems rarely care about neat averages alone.
In payments, operations, healthcare, and regulated decision systems, the rare events are often the ones with the highest significance.
That does not mean every classification problem is the same.
But it does mean that evaluation has to reflect the real objective of the system, not just the easiest number to report.
That is the shift I’m trying to internalise:
a useful model is not just a model with a good score
it is a model that fails in acceptable ways
What I’m taking from this week
My first takeaway is simple:
accuracy is a starting point, not a conclusion
The second is that evaluation should be tied to the actual cost of mistakes.
And the third is that once class imbalance enters the picture, model performance needs to be examined with much more care.
This still feels like early ground for me, but it is exactly the kind of ground I want to walk properly.
The better I understand how to evaluate simple models, the better foundation I’ll have when I start applying these ideas to more realistic systems later.
That is the real point of this stage of the journey.
Experiment artifacts
The practical experiment behind this note lives in my AI Learning Lab repository: