In Week 2 — Looking Beyond Accuracy, I wrote about why accuracy can be misleading.
That felt like an important shift. A model can look strong on paper while still failing in the exact places that matter most. Once I started looking at imbalanced datasets and confusion matrices, evaluation stopped feeling like a neat reporting exercise and started feeling more like system design.
This week is the next step in that same part of the learning plan.
Right now, I’m deliberately staying close to the foundations of supervised learning: not just training simple models, but learning how to evaluate them properly before moving on to more complex ideas. For me, that means taking the time to understand what different metrics are actually telling me.
What I explored this week
My focus this week was on precision, recall, and the idea that not all mistakes are equal.
That sounds obvious when written plainly, but it changes the way you look at model performance.
If a model raises too many false alarms, that creates noise, friction, and wasted effort.
If a model misses too many real positive cases, that can be even worse.
So the question is no longer just:
“How good is this model?”
It becomes:
“What kind of wrong can this system afford?”
That feels like a much more useful question.
Why this matters
One of the things I’m learning quickly is that evaluation metrics only become meaningful when they are tied to the real cost of error.
That is where precision and recall start to matter.
- Precision helps answer: when the model flags something, how often is it correct?
- Recall helps answer: of the cases that really matter, how many did the model actually catch?
Those are not interchangeable questions.
And depending on the system, one may matter far more than the other.
In some settings, false positives are annoying but manageable.
In others, false negatives are the real danger.
That trade-off is what I wanted to understand better this week.
Why this felt important early
I’m still at the beginning of this journey, which is exactly why I wanted to spend time here.
It is tempting to rush toward more complex models, bigger tools, or more impressive-sounding ideas.
But there is real value in learning how to judge a simple model properly before trying to build anything more ambitious on top of it.
A weak foundation can still produce exciting-looking outputs.
That does not make it a strong foundation.
The experiment
Following the questions above, I ran a small experiment to see how changing the decision threshold affects model behaviour.
I trained a simple logistic regression model on a synthetic imbalanced dataset (95% negative, 5% positive).
The model outputs probabilities, which are converted into decisions using a threshold.
I evaluated the same model at three thresholds:
- 0.50 (default)
- 0.30 (moderate)
- 0.10 (aggressive)
Results
Threshold comparison:
-
0.50
- Precision: 0.00
- Recall: 0.00
- F1: 0.00
- False Positives: 0
- False Negatives: 54
-
0.30
- Precision: 0.21
- Recall: 0.056
- F1: 0.08
- False Positives: 11
- False Negatives: 51
-
0.10
- Precision: 0.18
- Recall: 0.44
- F1: 0.26
- False Positives: 106
- False Negatives: 30
Visual
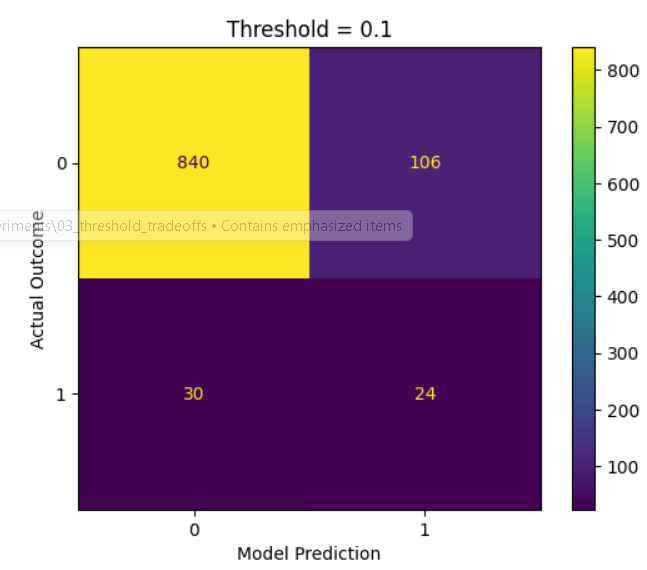
Interpretation
The model itself is not the issue.
The default threshold is too conservative for an imbalanced problem.
Lowering the threshold allows the system to capture more positive cases, but introduces additional false positives.
This demonstrates that model behaviour is highly dependent on how probabilities are converted into decisions.
Business Interpretation
In real-world scenarios such as fraud detection, missing a fraudulent transaction (false negative) is typically more costly than incorrectly flagging a legitimate one.
When false negatives carry a higher cost, lower thresholds can reduce overall system cost, even if precision decreases and more false positives are introduced.
This highlights that threshold selection should be driven by business risk and impact, not just model performance metrics.
Key Takeaway
The model didn’t change. The decisions did.
Threshold selection is not just a technical parameter — it defines system behaviour and must be aligned with real-world risk and cost.
Code & Experiment
Full notebook and outputs:
https://github.com/takhleeq-ai/AI-Learning-Lab/tree/main/experiments/03_threshold_tradeoffs